

 Supercharge Your Dev Team
Supercharge Your Dev Team  Secure Your Dev Team
Secure Your Dev Team  GitKraken Desktop
GitKraken Desktop GitLens for VS Code
GitLens for VS Code GitKraken CLI
GitKraken CLI GitKraken.dev
GitKraken.dev GitKraken Browser Extension
GitKraken Browser Extension Git Integration for Jira
Git Integration for Jira Pricing
Pricing
In April 2005, Linus Torvalds gave us a thousand lines of C code sprinkled with TODOs and comments about design decisions. This code was meant to be the basis of an “information manager” to help him develop the Linux kernel.
Git is the dominant version control system. If there was a version control war, Git won it. But why did Git become so popular, and what is the history of Git?
According to Richard Gabriel, creator of Lisp, it’s because ‘worse is better.’ That was the tongue-in-cheek answer he gave when asked why C language and the Unix operating system were ‘winning’ vs Lisp. He later went on to define ‘worse is better’ as a whole philosophy that has seen wide adoption.
The Philosophies of Software
To fit into the ‘worse is better’ philosophy, a piece of technology needs to hit four points:
1. Simplicity
2. Correctness
3. Consistency
4. Completeness
‘Worse is better’ is a philosophy that sits in contrast to another way of thinking called ‘the right thing’ or sometimes referred to as the MIT philosophy. ‘The right thing’ philosophy has the same overarching tenets of simplicity, correctness, consistency, and completeness.
How do these two philosophies differ? Let’s look first at ‘the right thing’ philosophy.

In ‘the right thing’ philosophy, when you look at the design of a system, you look first at its simplicity. The design and code must be simple, both in terms of its implementation and its interface. It must be simple to use. In fact, that last one, the simple to use UI, is the most important tenant, superseding the simplicity of implementation.
The next tenant says software must be correct. Incorrectness is not allowed, so you should ideally have a bug-free program.
Software must also consistently fit into ‘the right thing’. In fact, consistency is even more important than interface simplicity. You can cut a few corners in the simplicity area as long as the software remains consistent.
Finally, software must be complete. it must be usable and do all the things that a user would expect it to do.
These all sound like great tenants.
‘Worse Is Better’ vs ‘The Right Thing’
How does ‘the right thing’ compare with the ‘worse is better’ philosophy?
In the ‘worse is better’ approach, simplicity is also the first point, but there’s a bit of a twist. Instead of focusing on the user interface being simple, it’s more important that the implementation is simple. The code must be simple to understand and extend. This is more important than being simple to use.
Correctness in the ‘worse is better’ approach says software should be correct in all observable aspects, but it’s actually slightly better to be simple than correct. Simple implementation wins out over being totally correct, especially in early versions.
Designs under ‘worse is better’ need to be consistent, but it’s actually better to drop the parts of the design that deal with less common circumstances than to introduce complexity or inconsistency in the application, so again, simplicity of implementation wins.
Finally, completeness in ‘worse is better’ is important, but it can be sacrificed whenever implementation simplicity is jeopardized.
The core of ‘worse is better’ is building simple extendable code, not necessarily code that’s great to use, consistent, or necessarily complete.
This is admittedly a bit of a straw man argument, but as Richard Gabriel came to realize, software that adheres to the `worse is better` philosophy has a better survival rate than software embracing ‘the right thing’ worldview. That’s why C and Unix beat out Lisp in the long run.
Linux and Git and ‘Worse is Better’
There’s one person who stands out as adhering to the ‘worst is better’ philosophy better than any other software engineer: Linus Torvalds. Linus built the Linux kernel and also Git, the world’s most popular version control system. Those are two excellent examples of the ‘worst is better’ philosophy in practice.

The first time anybody heard of the Linux operating system was way back in 1991 when a young student named Linus posted on a Minix mailing list. Minix was a Unix-like OS from the late 80s. Linus had a 386 computer and was trying to learn how to program it at a very deep, low level to build an operating system on the 386 chip set.
In his early announcement, Linus noted that Linux will “never be a professional operating system”. However, the Linux kernel was incredibly popular. It took off really fast and filled a need that a lot of computer programmers had. People built distributions on top of his Linux kernel and a lot of the “user space” code, such as shells, to interact with the system like Bash, Zsh, or Tcsh.
Competing architectures coming out of places like MIT and the Free Software Foundation’s Gnu/Hurd project never really materialized as complete systems like Linux distributions did. This is because they were so focused on the architecture and getting it ‘just right’ that they never really got the code out the door.
Linux, with its ‘worse is better’ approach, won because it was released early and users could immediately build on top of it. Linus just announced something that he was building, even though it was hardly operational at the time, and then the world watched as it developed into a robust and powerful operating system. The well-thought-out and designed Gnu/Hurd kernel is still not at a v1.0 release after nearly 30 years.
Collaboration before Git
The Linux kernel was developed collaboratively as an open source project; arguably the most successful open source project that the world has ever seen. The way that collaborators worked was through a mailing list, much like the one Linus used to announce his initial ideas. People exchanged patches, wrote the code on their local machines, ran a diff, and then sent the output to the mailing list. If the maintainer of that particular kernel subsystem was interested in the change, they discussed it over the mailing list and eventually applied the change to the distribution for the next release.
Fundamentally, that is how changes got made to the Linux kernel in 2002. There was no true version control system. There was the project maintainer’s version of source code and that was it. Pretty quickly though, this collaboration system hit a scaling point where this was just too much manual activity. They needed a system to help, and that’s where BitKeeper came in.
From BitKeeper to Git
BitKeeper was the first distributed version control system. It added rigor on top of the mailing list system, making it easier to collaborate. The problem with BitKeeper was its license. It was a rather novel license model at the time, where BitKeeper charged for commercial use of their proprietary software but gave the Linux kernel developers a free, “open source” license. They could use it for free but they didn’t get the source code, and the license forbade reverse engineering BitKeeper. It also stated users couldn’t try to build a competing version control system. This led to some tension between some of the Linux kernel developers and the team behind BitKeeper. Ultimately the Linux community decided that they should find other options.
Then Came Mercurial
In the time between adopting BitKeeper and looking for alternatives, there were a number of other folks working on the distributed version control problem. Of note, in 2005 Matt MacKall posted on the Linux kernel mailing list announcing Mercurial v0.1 – a minimal scalable distributed SCM.

While Mercurial was in an early proof of concept stage, it was already doing surprisingly well and gaining fans. In Matt’s first message he noted some of the things that remain to be done for Mercurial, including all sorts of cleanup, packaging, documentation, and testing. This is a perfect example of a ‘worse is better’ approach. The funny thing was that the only response he got on the Linux kernel mailing list was someone telling him that it was too ‘worse is better.’
There is a common belief that if a tool is hard to use, poorly formatted, or poorly documented, people won’t use it no matter how great it is. That is in direct opposition to the philosophy of ‘worse is better.’ In fact, we can put the simplicity of the user interface aside so long as the code is simple. The code of Mercurial was outstanding, and that is how it became so popular.
Also in April 2005, Linus made an announcement on the Linux kernel mailing list in the same understated way that he originally announced Linux. He announced that he was writing some scripts to help him manage the patches on the Linux kernel mailing list. He said his scripts will not be a source control management system or a version control system, just something specific to his use case. Git was originally just some scripts Linus wrote to help with his use case, but he released the scripts early in development in case other contributors would find them helpful.
Managing Git (and Linux) Development
What Linus announced in April 2005 was the first version of Git. If you run a Git log on the Git Source Code Mirror repository you can see how the project looked and how it has grown over time. These first Git log messages are the first references of Git being “self-hosted,” meaning that the Git project was using Git to manage Git.
We’ve come a long way from Linus’ original post in 2005. It’s amazing how impactful and long-lasting Git’s dominance has been, especially when you think about the fact that it was originally only a handful of files, with just over 1,250 lines of code. It was incomplete and you could hardly do anything with it. At best, in its first form, Git was just a mechanism for a distributed file system.
As Linus said, it was not a version control system, nor an SCM. It was not consistent, nor really correct, especially around caching. It was certainly not simple, as you basically had to be Linus Torvalds to know how to use it. It was definitely not the Git that you see today.
Despite all those issues, people started using it. Specifically, the Linux kernel hackers started using it, because it simplified their lives in much the same way it simplified Linus’ life.
The hackers’ goal was to create patches for Linus to accept, while Linus’ goal was to manage and accept those patches. That is really what this system did.
Originally, there was no server-side component. This very much fits into the ‘worst is better’ philosophy: why build your own server when a service like Gmail can do it for you? At its core, it was about patches over email and it offloaded the actual hard bits—running a server that held the patches—to somebody else who already wrote a working version.
Was Linus’ goal satisfied? Yes. It got out there and got used. People started using it beyond just Linux kernel development and started using Git to manage Git development! Somebody could fix a bug in Git and send in a patch to the mailing list.
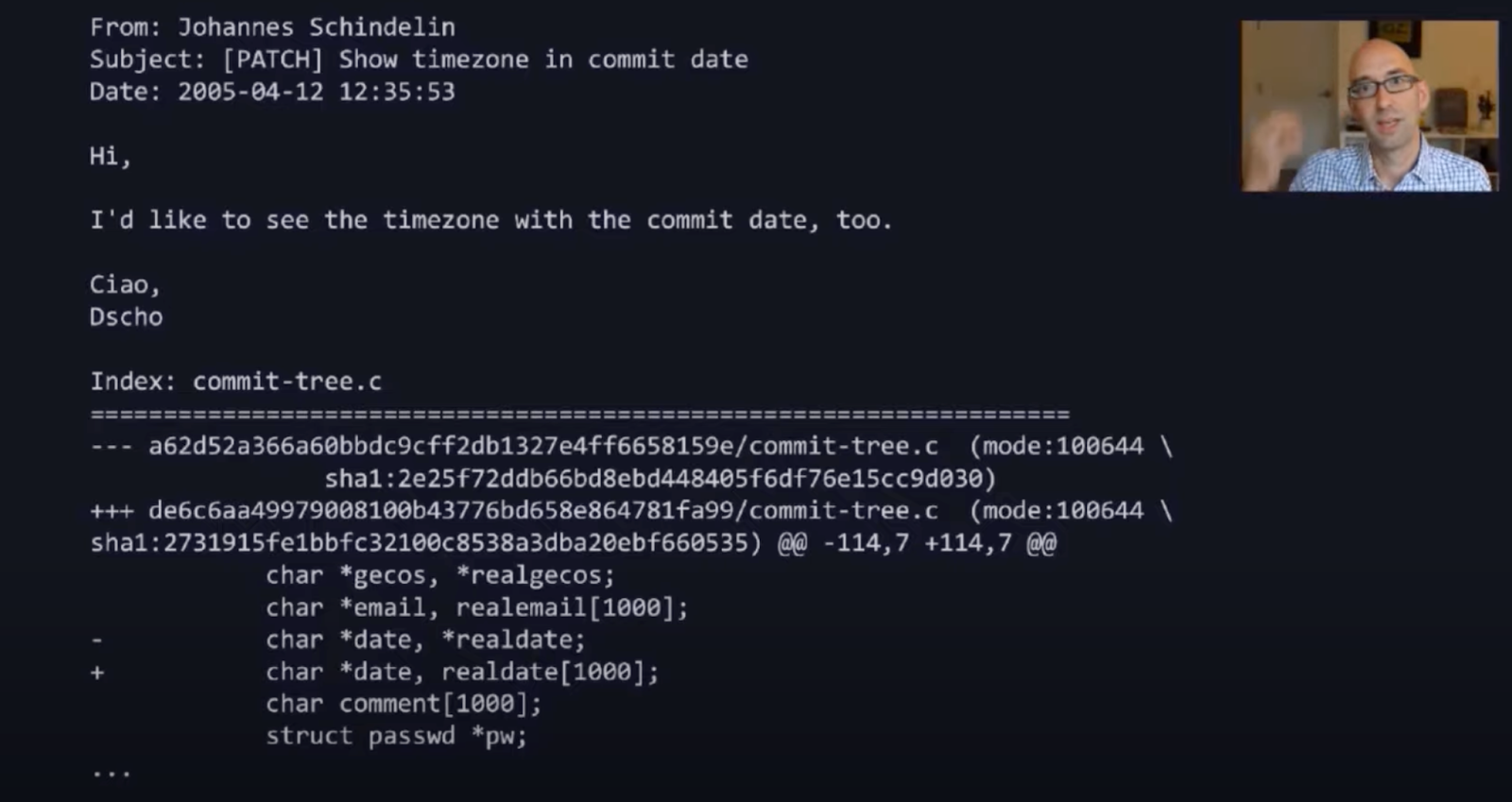
Git’s interface was not simple, but it was simple in its code, and that’s what allowed it to be extended. As Tom Preston-Werner, the co-founder of GitHub said, “Git makes collaboration possible but it doesn’t make it easy.” It makes a very specific form of collaboration possible, one that is very distributed and embraces an open source philosophy.
Opening Up Open Source
Open source is not very open if it’s hard to collaborate and only certain people hold the keys to the source code. Tom and his friends Chris Wanstrath and PJ Hyatt decided to tackle that problem and came up with GitHub.com.
GitHub came with the ability to host public repositories, making it really easy to send changes back and forth and discuss those changes. Instead of mailing a patch and waiting, you could suddenly open a Git pull request by just pushing your code up. You could fork a repository and work with branches to collaborate on any type of open source project. It really lowered the barriers to collaboration. It was revolutionary.
Git is simple in terms of its data structures and the code is very straightforward. Even if you don’t know graph theory, you will be impressed by the simplicity of the data structures after reading Git’s format documentation. The simple data structures allowed people to build other things on top of Git, like Git Endpoints in Heroku. Git also allows for simple deployment; just run a Git push.
Enter the Git Client
Git quickly went from just ‘another’ version control system, to the dominant version control system worldwide. As Git’s popularity grew, people started building both command line clients and Git GUI clients to make it easier to use.
Having a graph is helpful to visualize changes and branches. Being able to see Git diffs is also very helpful, making it easier to review changes or decide whether a Git rebase or Git merge would make more sense for certain commits. Since coming to market, developers building these tools have pushed the user interfaces to be more and more intuitive, satisfying the ‘simple’ of both ‘worse is better’ and ‘the right thing’ philosophies. Over the years, Git clients have evolved from rudimentary tools like gitk, to the click and point of TortoiseGit, and eventually to the drag-and-drop and beautiful commit graphs offered by the GitKraken Git client, which includes a GUI and CLI.
Git has given us a world where version control is easier to use and understand. A world where we have platforms that make collaboration and code deployment easier. There is a really vibrant ecosystem of Git tools that has evolved as a result of this ‘worse is better’ approach.
GitKraken is the perfect example of a Git tool that has evolved to meet new challenges, with advanced features like interactive pull request management, merge conflict detection and resolution, deep linking, and more.
From `git` to Git
We have also gone from Git being just the git command line application that Linus originally wrote and Junio Himano has maintained for years, to Git as a set of SCM protocols that allow you to manage Git repositories. Libraries such as libgit2, Jit, NodeGit, and pygit2 don’t have to call to a shell command to run git and parse that output. They can just execute any Git command, such as Git Commit, Git Branch, or Diff, directly against the file system, generating output in their respective programming languages. This is how Git services and tools can really scale.
The Winner is Git (and You)
Git won because it embraced the ‘worse is better’ philosophy. It didn’t worry about being complete or being necessarily correct, at least at first. Linus built a minimum viable product, ‘scratching his own itch’ as they say in the open source world. He built a small set of tools that were simple and easily implemented. He released them to the world and it’s now hard to underestimate the impact that Git has had on all areas of our software development.
Despite the fact that Git has won, there are still some areas where Git can be improved. Click here to check out the final section of Edward’s talk to hear about these areas and how Git can continue to evolve. Plus, you can see a live Q&A from the 2021 GitKon Git conference.
Take advantage now of all the work that Linus, Edward, and all the Git contributors have put into the most popular version control system and all the work the GitKraken team has done to make Git more usable through visualizations and a better UI by downloading the GitKraken Git client today, including a GUI and CLI!

